

Supervised Learning

A model learns from labeled training data using the machine learning technique of supervised learning in order to create predictions or categorizations. In order to teach the model how to relate input features to desired output labels, it must be trained using input features and input labels. Creating a predictive model that can accurately generalize and make predictions on fresh, untested data is the aim of supervised learning.

Brief Introduction to Machine Learning and Related Fields
The study of techniques and models that allow computers to learn and predict the future or make decisions without explicit programming is known as machine learning. It entails researching statistical methods and computer models to detect patterns and insights in data automatically.
Machine learning can be divided into a number of subfields, each with a special methodology and objective:
- Supervised Learning
In the machine learning branch of supervised learning, models are developed using labeled data made up of input features and associated output labels. In order to predict or categorize fresh, unobserved data, the model learns from these labeled examples. In order to build models that can comprehend intricate interactions between input and output variables and produce precise predictions across a range of domains, supervised learning is crucial.

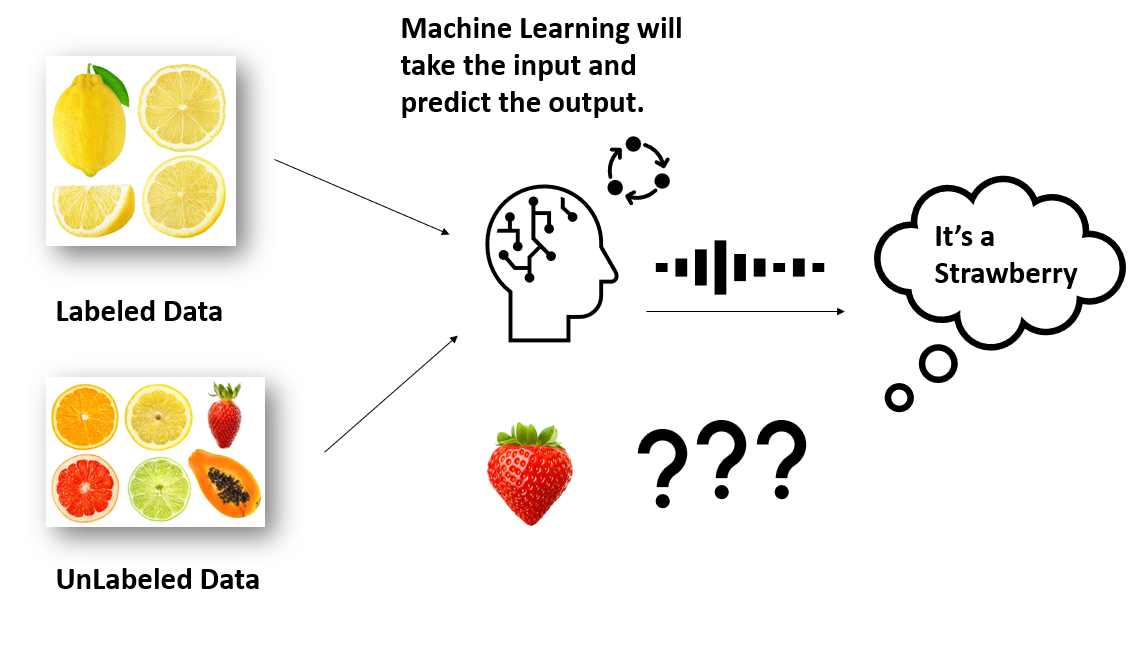
- Semi-Supervised Learning
Labeled and unlabeled data are used for training in semi-supervised learning, a hybrid method. It uses a smaller set of labeled data and a larger set of unlabeled data to create models that can categorize or predict data. In order to overcome the difficulty of obtaining labeled data, which might be costly or time-consuming, semi-supervised learning is crucial. When there is a dearth of labeled data, it enables models to draw from a bigger pool of unlabeled data, improving performance.

- Self-Supervised Learning
Self-supervised learning uses surrogate tasks to help models learn from unlabeled data. By learning usable representations without explicit labeling, the models are efficiently trained to predict missing or distorted portions of the input data. Self-supervised learning is crucial because it allows models to gain knowledge from enormous amounts of easily accessible unlabeled data. It can greatly lessen the dependency on labeled data and has demonstrated promising outcomes in a number of fields, including computer vision and natural language processing.
The benefit of supervised learning in resolving real-world problems
In order to solve problems in the real world across many different disciplines, supervised learning is essential. Here are some crucial details emphasizing the value of supervised learning:

- Accurate Predictions and Decision Making: Using the labeled data that is now available, supervised learning algorithms enable accurate predictions and well-informed decision-making. These algorithms are able to make predictions or classify new, undiscovered cases with a high degree of accuracy because they learn patterns and relationships from prior data.
- Supervised learning techniques have a broad range of applications, including the classification and regression of problems. Supervised learning offers a flexible framework to address a variety of real-world difficulties, including predicting customer churn, identifying fraudulent transactions, diagnosing diseases, and identifying objects in photos.
- Data-Driven Perspectives Organizations can use supervised learning to get important insights from their data. Businesses can make data-driven decisions, optimize processes, spot trends, and find hidden patterns by examining and comprehending the connections between input attributes and output labels. These links may not be seen through manual analysis.
- Automation and Efficiency: Supervised learning reduces time and effort by automating prediction and decision-making processes. Using trained models, tasks that would normally require manual intervention or expert judgment can be expedited, resulting in effective and scalable solutions.
- Supervised learning is the driving force behind recommendation systems and personalized experiences. These systems can give specialized recommendations, product suggestions, and content recommendations by examining user preferences and behavior, increasing user satisfaction and engagement.
- Healthcare and medical diagnostics: In the field of medicine, supervised learning aids in disease prognosis, diagnosis, and therapy planning. In order to assist in early detection, offer individualized treatment recommendations, and help medical personnel make more precise diagnoses, trained models can assess patient data, medical imaging, and genetic information.
- Financial Analysis and Fraud Detection: Supervised learning is essential for conducting financial analysis, assigning credit scores, and identifying fraud. Models may analyze risk, forecast stock market trends, assess creditworthiness, and spot abnormalities that could be signs of fraud, assisting organizations in reducing risk and making wise financial decisions.
- Supervised learning algorithms perform exceptionally well in natural language processing applications including sentiment analysis, text categorization, and language translation. With the aid of these tools, massive amounts of textual data can be analyzed, making it feasible to glean insightful information from client comments, social media opinions, and reviews.
Basic Idea
- In supervised learning, an algorithm uses labeled training data to generate predictions or choices on brand-new, unlabeled data. In order to build a model that can generalize and make precise predictions on unobserved data points, supervised learning relies on the knowledge of input features (independent variables) and their associated output labels (dependent variables).

- In supervised learning, pairs of input feature vectors and their associated known output labels make up the training data. While the output labels indicate the desired result or goal variable, the input features represent the qualities or aspects of the data. Based on the given labeled samples, the objective is to learn a mapping or relationship between the input attributes and output labels.
- The algorithm uses the labeled data during the training phase to modify its internal parameters and enhance its capacity to predict the right output label given fresh input information. To buildthe model that can generalize and make precise predictions on unobserved data, the algorithm learns patterns, correlations, and underlying structures in the training data.
- Once trained, the model can be used to anticipate the output labels for a novel, unforeseen input features. In order to make predictions or choices based on the patterns it has learned from the labeled training examples, the model applies the learned mapping or connection to the incoming data.
- In supervised learning, it is essential to make a clear difference between input features and output labels. Given the model as input, the input features are regarded as independent variables, whilst the output labels are dependent variables that the model seeks to predict or categorize based on the input features. By being aware of this difference, we may train the model to accurately anticipate data that hasn't yet been observed by teaching it the relationship between input attributes and output labels.
- Overall, supervised learning offers a strong framework for tackling prediction and classification problems by learning from labeled training data, creating a clear relationship between input features and output labels, and using this understanding to generate predictions on fresh, a priori data.
Principals of Supervised Learning
- Knowledge of the Foundation(Input Features and Output Labels): Descriptions of the input features in detail Discover the traits, properties, or variables that make up the supplied data. Explain the selection or engineering processes used to create these features to capture the information necessary for the learning objective.
- Descriptions of output labels in detail: Make sure to draw attention to the variable that the model is trying to predict or classify, as well as the desired result. Talk about the output labels' nature, such as whether they are continuous (numerical values) or categorical (class labels).
- Build the foundation for learning by using training data, Labeled training data are crucial because they describe the principles of supervised learning and how they are based on labeled instances.
- Training data representation: Show how the training data is organized, which is often as a set of labeled instances, each of which consists of input features and the output labels that go with it. Discuss the data's structure and format, such as if it is in tabular form, an image dataset, or a corpus of text.
- Examples and visualizations that Demonstrate the Relationship: Showcase some instances of input features and the labels for the related outputs: Give specific instances or use case studies to demonstrate how the input attributes and output labels relate to one another. Show how changes to the input features have an impact on the matching output labels.
- Scattered plots, line plots, or bar charts are good visualizations to use to demonstrate the relationship between the input attributes and the output labels. Describe how patterns, correlations, or trends can be visualized.
- By covering the crucial elements of supervised learning, such as input features, output labels, and the function of training data, as well as by giving informative examples and visualizations, readers may obtain a complete knowledge of the fundamental ideas behind the technique.
Popular Supervised Learning Algorithms

- Regression: A straightforward approach for regression issues in which the objective is to forecast a continuous value based on input features is known as linear regression. Another sort of regression technique utilized for classification issues is logistic regression, whose objective is to forecast discrete class labels.
- Decision Trees: These tree-based algorithms divide the feature space into more manageable areas in accordance with decision rules, creating a hierarchical structure that may be applied to both regression and classification tasks.
- Random Forest: A prediction-making ensemble technique that incorporates many decision trees. It offers robustness against overfitting and can handle problems involving both classification and regression.
- Gradient Boosting: A boosting technique that sequentially creates an ensemble of ineffective learners (usually decision trees), with each new learner attempting to fix the errors of the preceding ones.
- Support Vector Machines (SVM) is a flexible technique for categorizing data points into various groups by building hyperplanes or sets of hyperplanes in a high-dimensional space.
- Naive Bayes is a probabilistic algorithm that relies on the independence of characteristics in Bayes' theorem. It is frequently employed for applications like text classification and spam filtering.
- K-Nearest Neighbors (KNN) is a non-parametric technique that bases predictions on the feature space's k nearest training instances. It can be applied to classification and regression issues.
- Deep learning algorithms known as neural networks, which are based on the organization and operation of biological brains, are made up of interconnected layers of synthetic neurons. They are frequently employed for several tasks, such as voice and picture recognition, and they have the ability to model complex relationships.
- Ensemble approaches (such as AdaBoost and Bagging): These techniques integrate various models to increase the precision of predictions. They take advantage of the wisdom of the masses and lessen the effects of flaws in particular models.
- There are many more common supervised learning algorithms available, depending on the particular issue you're attempting to resolve. These are but a few examples. The type of data, problem complexity, and desired performance indicators all play a role in the algorithm selection process.
Process of Model Training in Supervised Learning

- Data gathering: Compile a dataset of samples with labels. Each example has input features (X) and associated target values or class labels (Y), which are known as labeled data.
- Data Preprocessing: Perform a number of preprocessing operations on the data to get it ready for training, including handling missing values, encoding categorical variables, scaling features, and dividing the data into training and validation/test sets.
- Choosing a Model: Based on the situation at hand and the data's properties, choose an appropriate supervised learning approach. Take into account variables including model complexity, interpretability, and computational needs.
- Defining the Model: Establish the chosen model's architecture or structure. For instance, you define the input features, coefficients, and bias terms in linear regression. You can define the amount and types of layers, activation mechanisms, and connections between neurons in neural networks.
- Initializing the Model: Use random initialization methods or specified initialization approaches to initialize the model's parameters or weights. A good initialization can speed up convergence and improve performance.
- In order to minimize a specified loss function, iteratively change the model's parameters after feeding it training data. On the basis of the training data, the model produces predictions, compares them to the true labels, determines the loss, and then modifies the parameters using optimization algorithms (such as gradient descent) in order to minimize the loss.
- Evaluation of Model Performance: After Training, evaluate the model's performance on Unknown Data. Use evaluation criteria that are specific to the issue, such as R-squared, and F1-score for classification, accuracy, precision, and recall. To make sure the model generalizes successfully, evaluate its performance on the validation/test set.
- Hyperparameter Tuning: To further enhance the performance of the model, adjust its hyperparameters. Hyperparameters are settings made before training that have an impact on how well something learns (e.g., learning rate, regularization strength). To determine the ideal hyperparameter values, techniques like grid search, random search, or more sophisticated techniques like Bayesian optimization can be used.
- When you are pleased with the model's performance, you can use it to produce forecasts based on fresh, unforeseen data.
- Monitoring & Upkeep: Keep an eye on the model's performance in the real-world setting, keep tabs on its forecasts, and determine whether it needs retraining or updates. This stage makes the model reliable and current throughout time.
- It's crucial to remember that this is only a broad description of the model training process; specifics will rely on the algorithm, problem area, and resource availability.
Evaluation of Models: Measuring the Performance of Trained Models

- Accuracy: The ratio of cases that were successfully classified to all instances. It gives a broad indication of the model's forecasting ability.
- The ratio of genuine positives to the total of true positives and false positives is known as precision. It shows how well the model can recognize good occurrences.
- The ratio of true positives to the total of true positives and false negatives is known as Recall (also known as sensitivity or true positive rate).
- It evaluates the model's capacity to identify each positive event.
- The synergistic average of recall and accuracy is the F1 score. It provides a fair assessment of a model's effectiveness.
- Area or AUC-ROC The ability of a model to discriminate between positive and negative events at various categorization criteria is measured using the ROC Curve. Performance improves as AUC-ROC increases.
- The mean squared error, or MSE, is the squared difference between the expected and actual numbers. Between the values of the forecasts and the actual values, it computes the average squared deviation.
- The mean squared error (RMSE) is the square root of the root MSE. It provides a solution by showing the error in the target variable's initial scale.
- The mean of the absolute discrepancies between the expected and actual values is known as the mean absolute error (MAE). It calculates the average absolute difference between the projections' values and the actual values.
- R-squared (Coefficient of Determination): The percentage of the target variable's variance that the model can account for. It has a value between 0 and 1, with 1 denoting a perfect match.
- A measure of how well instances in one cluster are distinguished from instances in other clusters is the silhouette coefficient. A value close to 1 denotes good clustering, and the scale runs from -1 to 1.
- A measure of the average similarity and dissimilarity between clusters is the Davies-Bouldin index. Better clustering is indicated by lower values.
- A statistic frequently used in information retrieval and recommendation systems is mean average precision (MAP). It calculates the typical precision at each rank before averaging the results across all levels.
- The metric known as Normalized Discounted Cumulative Gain (NDCG) assesses the value of a ranked list. It considers both the relevancy and item rank positions.
- K-fold Cross-Validation: This method separates the data into k subsets or folds, performs training and evaluation on each fold k times, and uses each fold as the validation set k times. By lessening reliance on a single train-test split, it offers a more reliable estimate of model performance.
Take into consideration that while assessment measures might shed light on a model's performance, they shouldn't serve as the only standard by which to assess the model's efficacy. It is also important to take into account elements like interpretability, computational needs, and particular application requirements.
Applications of Supervised Learning: Leveraging the Potential of Labeled Data

- Image and Object Recognition: Supervised learning approaches have been used to complete tasks for image segmentation, picture classification, and object detection. These algorithms may be taught to recognize and classify objects in images, which makes them advantageous for use in surveillance systems, self-driving automobiles, medical image analysis, and facial recognition.
- Assisted learning is necessary for Natural Language Processing (NLP) tasks like sentiment analysis, text categorization, named entity recognition, machine translation, and question-answering.
- These algorithms can comprehend and produce human language by training models on tagged text data, opening the door to applications like chatbots, language translation services, and sentiment analysis for consumer feedback.
- Voice and Audio Processing: Applications for voice recognition and audio processing heavily rely on supervised learning. For tasks including speech recognition, speaker identification, speech synthesis, and noise cancellation, methods like Hidden Markov Models (HMMs) and deep learning-based models such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been used.
- Fraud Detection: On labeled data containing information about fraudulent and non-fraudulent transactions, supervised learning algorithms can be trained.
- Healthcare and Medical Diagnosis: Medical image analysis, disease diagnosis, and patient monitoring all make extensive use of supervised learning techniques. To help clinicians diagnose diseases, forecast outcomes, and recommend individualized treatment options, these algorithms can examine patient data, electronic health records (EHRs), and medical pictures.
- Systems for providing personalized suggestions to users based on their interests and actions can be created using supervised learning algorithms. As seen on sites like Netflix, Amazon, and Spotify, these systems can recommend movies, products, or material that are probably of interest to consumers by learning from labeled data.
- Credit Scoring: To evaluate creditworthiness and decide whether to approve a loan, financial organizations utilize supervised learning algorithms. These algorithms can forecast the risk associated with new loan applicants by training models on historical data that contains labeled information about loan applicants' credit profiles and repayment histories.
- Maintenance Prediction: Supervised learning can be used to forecast breakdowns or upkeep requirements for machinery and equipment. These algorithms can find patterns and indicators that presage failures by evaluating labeled data relating to sensor readings, past maintenance records, and failure events. This enables proactive maintenance and decreases downtime.

