

Learning Curve
A learning curve in deep learning is a graphical representation of the relationship between a model's performance on a task and the amount of training data needed to train the model. It is a plot of a performance parameter, such as accuracy or error rate, against the size of the training set or the number of training rounds.

Introduction
A learning curve is a tool widely used to assess a model's effectiveness and identify any problems that may exist. The error rate normally decreases as training data increases, since the model has more instances to learn from and can better generalize to new examples.
Deep learning curves are classified into two types: training curves and validation curves. The training curve depicts the model's performance on training data. Still, the validation curve depicts the model's performance on a different validation set, which is used to assess the model's ability to generalize to new examples. As the model is trained, the two curves should converge, suggesting that the model is not overfitting to the training data.
- A learning curve is a plot showing model learning performance over time.
- The model can be tested on the training dataset and a hold-out validation dataset after each update during training, and visualizations of the Learning curves can be generated using measured performance.
- Examining model learning curves during training can be used to diagnose learning issues such as an underfit or over fit model, as well as whether the training and validation datasets are sufficiently representative.
Learning Curve Interpretation
It is usual practice to evaluate the performance of a machine learning model on both training and validation data sets during the training process. The validation set is a different subset of the data that is not used during training but rather acts as a surrogate for evaluating the model's generalization capacity. The training error represents the model's error rate on the training set, whereas the validation error represents the model's error rate on the validation set.
How the learning rate progresses, such as low, very high, and good learning rates. The plot depicts the training and validation accuracy of a type of overfitting, such as little and strong overfitting.
- The learning rate is a hyperparameter that defines the step size at each iteration while improving the model parameters during training. A low learning rate might cause the training process to converge slowly, whereas a very high learning rate can cause the optimization process to overshoot the optimal solution, resulting in unstable training. A good learning rate strikes a balance between these two extremes, resulting in stable and efficient training.
- Training and validation accuracy: Training accuracy is the performance metric that measures how well a model fits the training data during training, whereas validation accuracy is the performance metric that measures how well the model generalizes to unknown data.
- It's important to evaluate the two things while training a model that is testing accuracy and validation accuracy and to ensure that the model is a good fit for the model and not overfitting to the training data. when the model is excessively complicated or flexible, such as having too many parameters in relation to the amount of training data.
- This allows the model to learn noise or irrelevant properties in the input, which can impair its capacity to generalize to new data which leads to high training accuracy with poor accuracy in its validation.
- little and strong overfitting: Little overfitting takes place when the model has both the training and the validation accuracy high but in that, the validation accuracy is a little bit low compared to the training accuracy.
- Strong Overfitting will happen when the validation accuracy is much lower, and the training accuracy is very high and indicating that it is not generalizing the new data instead it is memorizing the training data.
- To prevent all problems in overfitting the techniques used are regularization, early stopping, and data argumentation can be used.
- The training and validation accuracy of the model in which there is an unrepresentative training set and we need to increase the size training set in order to good fit the training of the model.
- We indicated that when a model learns noise too quickly, the validation loss may begin to grow during training. To avoid this, we may simply halt the training once it appears that the validation loss is no longer lowering. This method of interrupting training is known as early stopping.
- When the validation loss begins to grow again, we can reset the weights to where the minimum occurred. This prevents the machine from learning noise and overfitting the data.
Training with an early ending also reduces the risk of terminating the training too soon, before the network has finished learning the signal.
.png)
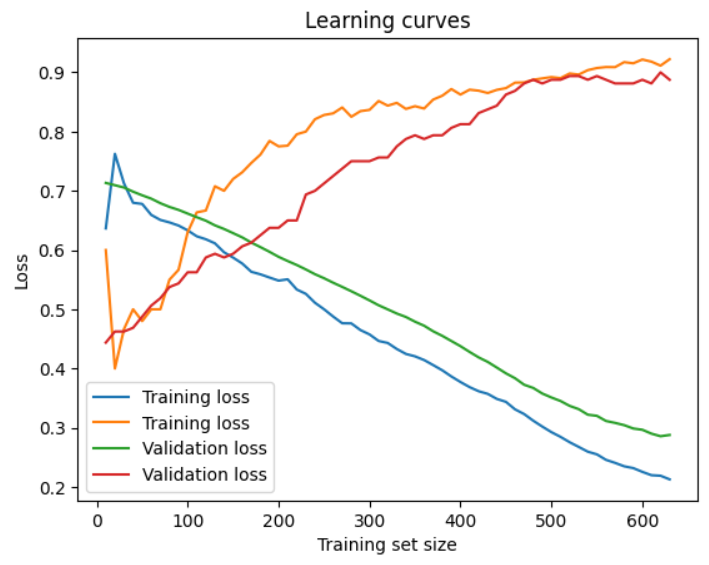
- The training and validation errors of a learning curve is a graph that depicts how training and validation mistakes change as the number of training repetitions or epochs rises. It's a handy tool for assessing model performance during training and recognizing potential issues like overfitting.
- The x-axis of the learning curve shows the number of training iterations or epochs, while the y-axis reflects the mistake rate.
- The training error curve depicts how the error rate lowers when the model is trained on more data. The validation error curve, on the other hand, demonstrates how effectively the model generalizes to new data as training advances.
- Both curves should ideally decline, and the distance between them should not be too significant. If the gap between the two curves begins to increase, this is an indicator of overfitting, in which the model begins to memorize the training data rather than learn the general pattern. At this stage, you might want to think about utilizing regularization techniques like dropout or L2 regularization to prevent overfitting.
- The training and validation data set accuracy of the model in which there is an unrepresentative Validation set and we need to increase the size validation data set in order to good fit the training of the model.
Implementation
Let's implement the sample code in Python using the digits dataset and its visualize the output.
Source code
# Import the Required Libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
# Load the dataset
digits = load_digits()
X = digits.data
y = digits.target
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the model
model = MLPClassifier(hidden_layer_sizes=(64, 64), activation='relu', random_state=42)
# Initialize lists to store the training and validation scores
train_scores = []
val_scores = []
# Vary the training set size and evaluate the model
for i in range(10, len(X_train), 100):
X_subset = X_train[:i]
y_subset = y_train[:i]
model.fit(X_subset, y_subset)
train_score = model.score(X_subset, y_subset)
val_score = model.score(X_val, y_val)
train_scores.append(train_score)
val_scores.append(val_score)
# Plot the learning curves
plt.plot(range(10, len(X_train), 100), train_scores, label='Training Score')
plt.plot(range(10, len(X_train), 100), val_scores, label='Validation Score')
plt.xlabel('Training Set Size')
plt.ylabel('Accuracy')
plt.title('Learning Curves')
plt.legend()
plt.show()
.png)
Description
- For this example, we use the 8x8 photos of handwritten numbers from the digits dataset from scikit-learn. The code and visualization are explained in the following manner:
- We load the required libraries, such as Matplotlib for plotting, Scikit-Learn for the dataset and model, and Scikit-Learn modules. NumPy is used for numerical computations.
- The scikit-learn load_digits function is used to load the digits dataset. The dataset includes the target labels y and the input attributes X.
- Using the train_test_split function, the data is divided into training and validation sets. 20% of the data in this case is utilized for validation, while the remaining 80% is used for training.
- We use scikit-learn's MLPClassifier class to define the model. The model is a 64-unit multi-layer perceptron (MLP) with two hidden layers. The rectified linear unit activation function is what is indicated by the activation parameter, which is set to'relu'.
- To store the training and validation scores, we establish empty lists.
- We do iterations with training set sizes ranging from 10 to 100. We train the model using a portion of the training data for each iteration and assess its performance on the validation set. The scoring method, which determines the model's correctness, is used to compute the training and validation scores.
- The corresponding lists are supplemented with the training and validation scores.
- Finally, we use Matplotlib to plot the learning curves. The training set size is represented by the x-axis, while accuracy is represented by the y-axis. As the training set size grows, the learning curves demonstrate the trend in the training score and validation score. We can analyze the trade-off between bias and variance and determine if the model is underfitting or overfitting by looking at the learning curves.
- The learning curves are presented as the code's output. The training score's learning curve demonstrates how the model's accuracy on the training set changes as the amount of data increases. The validation score's learning curve reveals the validation set's correctness. We can spot patterns like overfitting, underfitting, or convergence to an ideal performance by comparing these curves.
Key Points to Remember
- High training accuracy but low validation accuracy indicates overfitting, in which the model memorizes the training data rather than learning the general pattern.
- Techniques like regularization and early halting can be used to prevent overfitting.
- Low training and validation accuracy: This shows that the model is underfitting and is failing to understand the overall pattern of the data.
- To increase model performance, consider increasing the model's complexity, adding additional features, or increasing the training duration.
- Both training and validation accuracy is improving: This indicates that the model is learning and improving its performance as additional data is loaded into it.
- However, if the validation accuracy begins to stall as the training accuracy improves, this may be a symptom of overfitting.
- The difference in training and validation accuracy is growing: This implies that the model is overfitting, which occurs when the machine begins to memorize the training data rather than learning the general pattern.
- To avoid overfitting, try employing approaches such as regularization or early stopping.
Conclusion
In general, learning curves are a crucial tool for measuring a machine learning model's performance during the training process. Analyzing the learning curves can provide information about how the model is learning and whether there are any concerns such as overfitting. Overall, learning curves can provide important insights into your machine learning model's performance during the training process, allowing you to diagnose problems and improve the model's performance.

